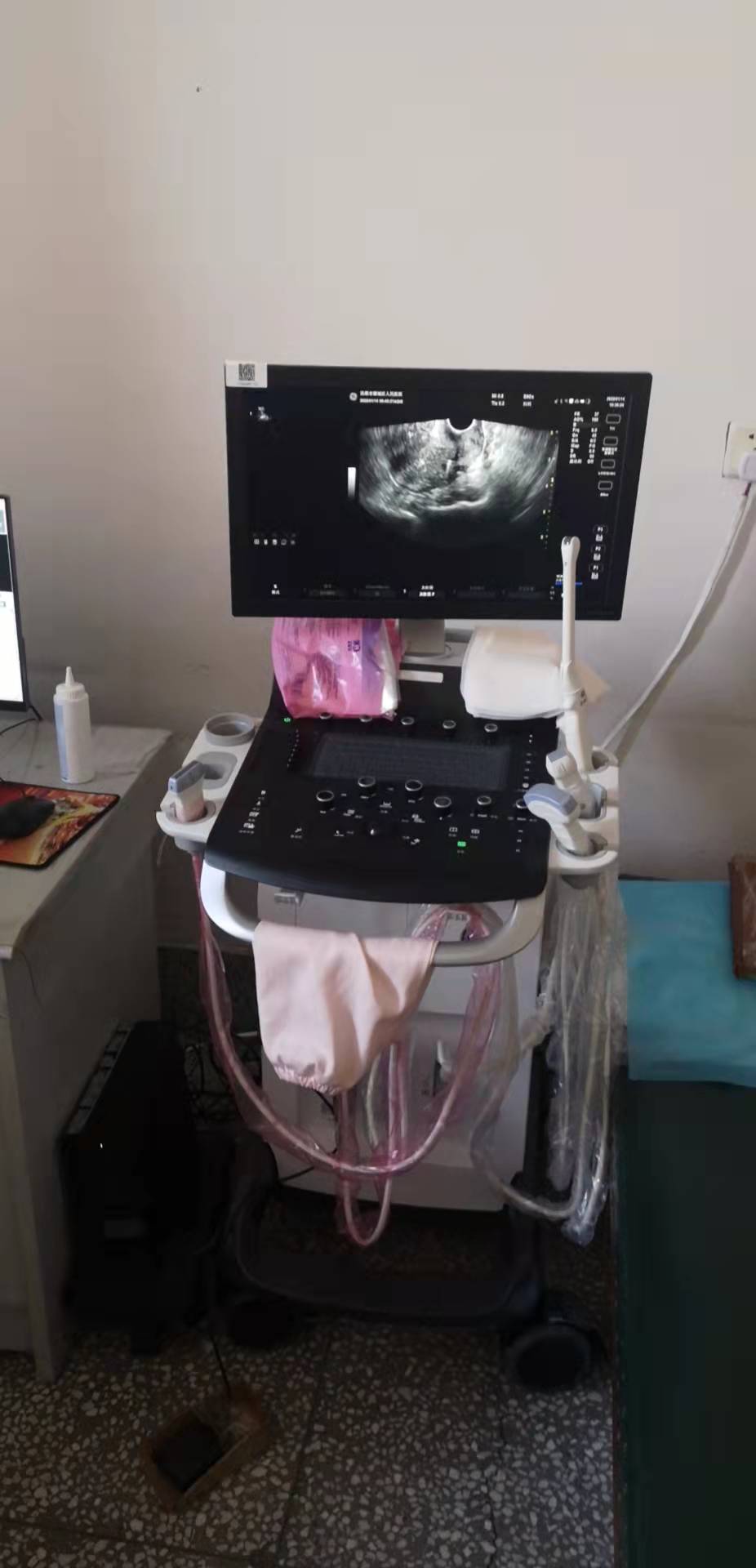
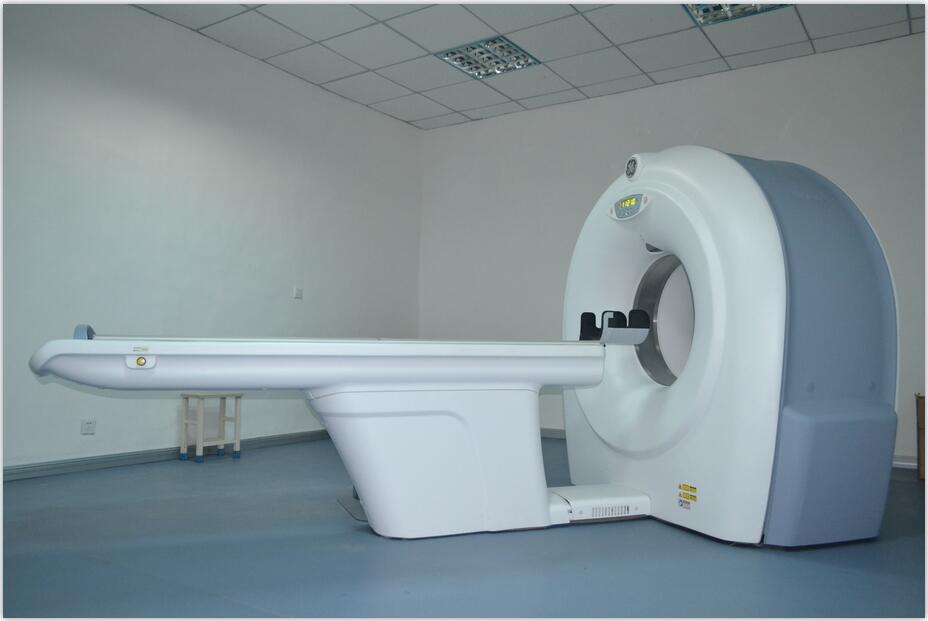
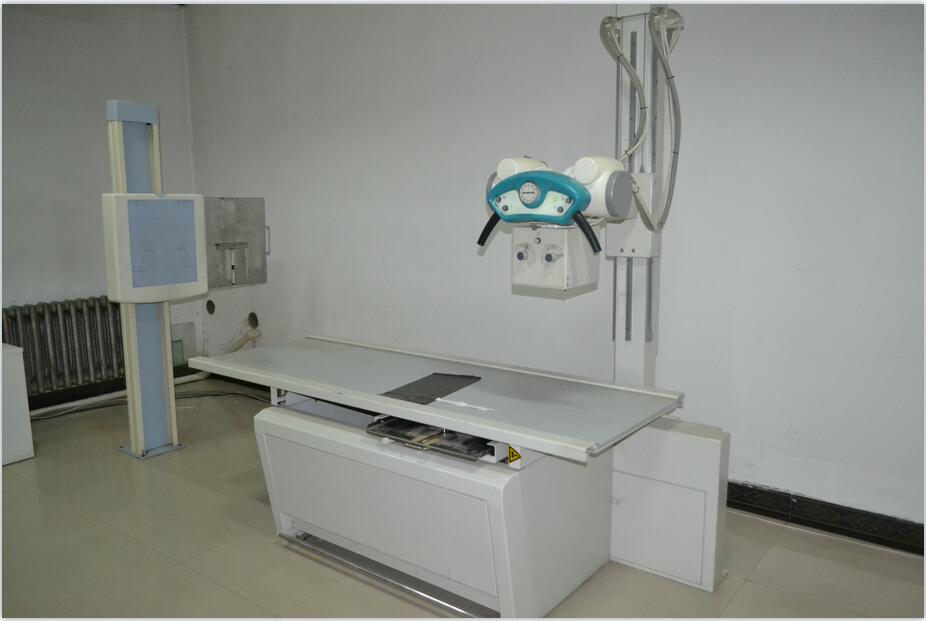
歡迎訪問(wèn)“撫順市順城區(qū)人民醫(yī)院”官方網(wǎng)站!
 024-5760 3266024-5760 3266
024-5760 3266024-5760 3266 撫順市順城區(qū)人民醫(yī)院外觀
撫順市順城區(qū)人民醫(yī)院外觀 撫順市順城區(qū)人民醫(yī)院門(mén)診
撫順市順城區(qū)人民醫(yī)院門(mén)診 撫順市順城區(qū)人民醫(yī)院國(guó)醫(yī)堂
撫順市順城區(qū)人民醫(yī)院國(guó)醫(yī)堂

地址:順城區(qū)新城路東段長(zhǎng)春街
版權(quán)所有:撫順市順城區(qū)人民醫(yī)院
備案號(hào):遼ICP備11019000號(hào)
 遼公網(wǎng)安備
21041102000408號(hào)
遼公網(wǎng)安備
21041102000408號(hào)

微信二維碼